
【动态规划】关于动态规划优化,其实不难
这篇文章更多讲解我平时做题的套路,不过由于篇幅过长,举了 4 个案例之后,没有讲解优化,今天这篇文章就来讲解下,对动态规划的优化如何下手,并且以前几天那篇文章的题作为例子直接讲优化,如果没看过的建议看一下(不看也行,我会直接给出题目以及没有优化前的代码):告别动态规划,连刷40道动规算法题,我总结了动规的套路
优化核心:画图!画图!画图
没错,80% 的动态规划题都可以画图,其中 80% 的题都可以通过画图一下子知道怎么优化,当然,DP 也有一些很难的题,想优化可没那么容易,不过,今天我要讲的,是属于不怎么难,且最常见,面试笔试最经常考的难度的题。
下面我们直接通过三道题目来讲解优化,你会发现,这些题,优化过后,代码只有细微的改变,你只要会一两道,可以说是会了 80% 的题。
O(n*m) 空间复杂度优化成 O(n)
上次那个青蛙跳台阶的 dp 题是可以把空间复杂度 O( n) 优化成 O(1),本来打算从这道题讲起的,但想了下,想要学习 dp 优化的感觉至少都是 小小大佬了,所以就不讲了,就从二维数组的 dp 讲起。
案例1:最多路径数
问题描述
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
问总共有多少条不同的路径?

这是 leetcode 的 62 号题:https://leetcode-cn.com/problems/unique-paths/
这道题的 dp 转移公式是 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1],代码如下
不懂的看我之前文章:告别动态规划,连刷40道动规算法题,我总结了动规的套路
这种做法的空间复杂度是 O(n * m),下面我们来讲解如何优化成 O(n)。
dp[i] [j] 是一个二维矩阵,我们来画个二维矩阵的图,对矩阵进行初始化
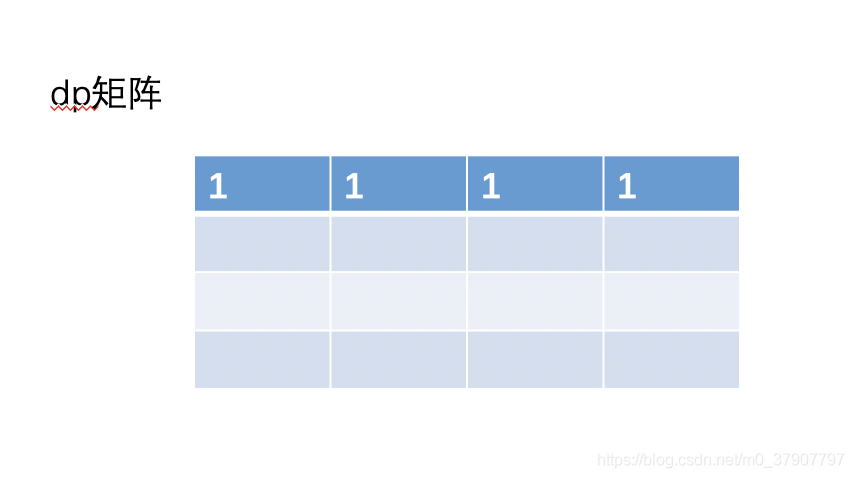
然后根据公式 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1] 来填充矩阵的其他值。下面我们先填充第二行的值。
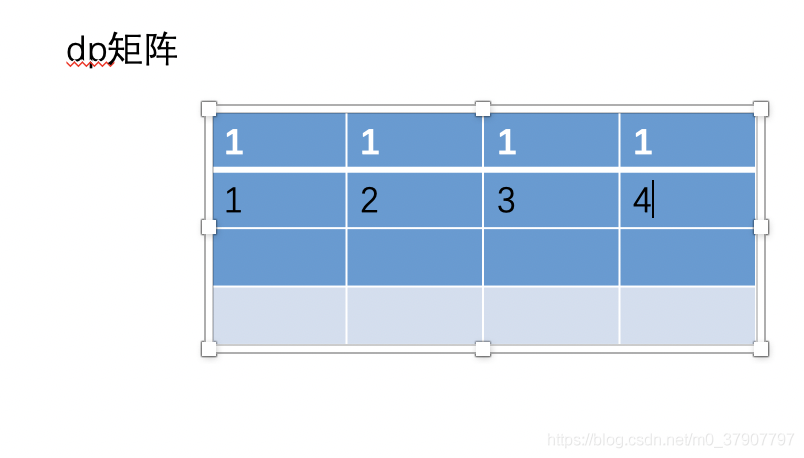
大家想一个问题,当我们要填充第三行的值的时候,我们需要用到第一行的值吗?答是不需要的,不行你试试,当你要填充第三,第四….第 n 行的时候,第一行的值永远不会用到,只要填充第二行的值时会用到。
根据公式 dp[i] [j] = dp[i-1] [j] + dp[i] [j-1],我们可以知道,当我们要计算第 i 行的值时,除了会用到第 i – 1 行外,其他第 1 至 第 i-2 行的值我们都是不需要用到的,也就是说,对于那部分用不到的值我们还有必要保存他们吗?
答是没必要,我们只需要用一个一维的 dp[] 来保存一行的历史记录就可以了。然后在计算机的过程中,不断着更新 dp[] 的值。单说估计你可能不好理解,下面我就手把手来演示下这个过程。
1、刚开始初始化第一行,此时 dp[0..n-1] 的值就是第一行的值。
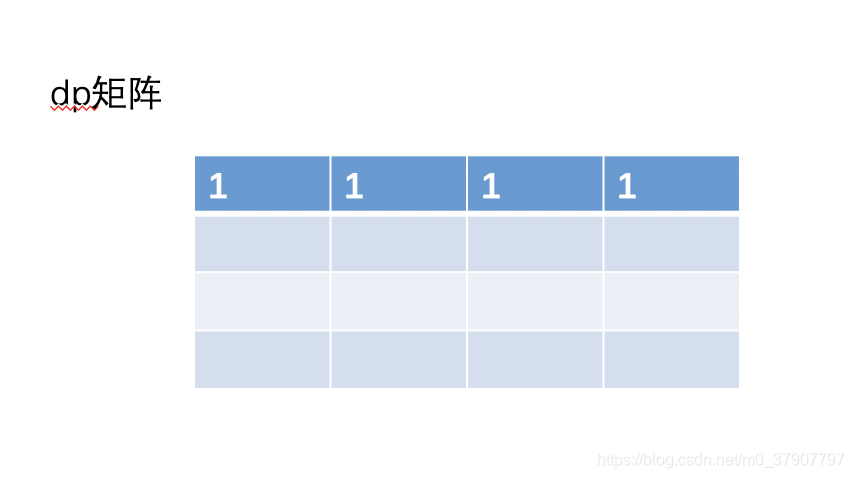
2、接着我们来一边填充第二行的值一边更新 dp[i] 的值,一边把第一行的值抛弃掉。
为了方便描述,下面我们用arr (i,j)表示矩阵中第 i 行 第 j 列的值。从 0 开始哈,就是说有第 0 行。
(1)、显然,矩阵(1, 0) 的值相当于以往的初始化值,为 1。然后这个时候矩阵 (0,0)的值不在需要保存了,因为再也用不到了。
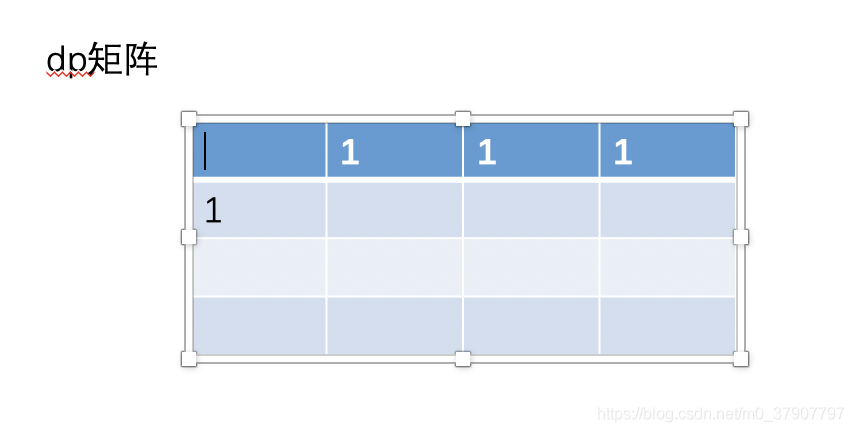
这个时候,我们也要跟着更新 dp[0] 的值了,刚开始 dp[0] = (0, 0),现在更新为 dp[0] = (1, 0)。
(2)、接着继续更新 (1, 1) 的值,根据之前的公式 (i, j) = (i-1, j) + (i, j- 1)。即 (1,1)=(0,1)+(1,0)=2。
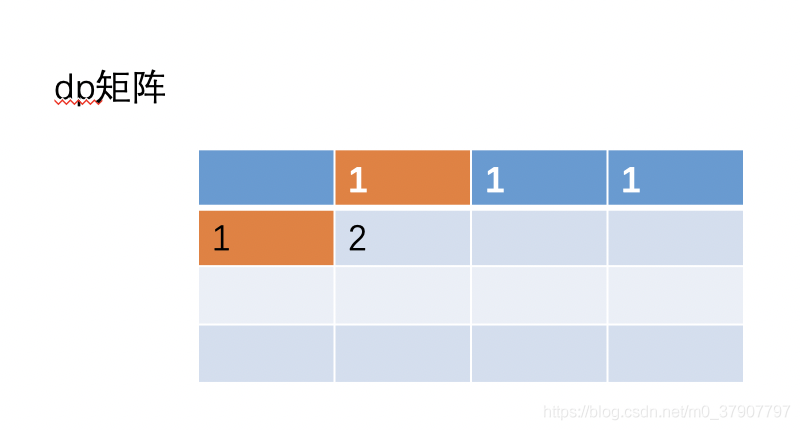
大家看图,以往的二维的时候, dp[i] [j] = dp[i-1] [j]+ dp[i] [j-1]。现在转化成一维,不就是 dp[i] = dp[i] + dp[i-1] 吗?
即 dp[1] = dp[1] + dp[0],而且还动态帮我们更新了 dp[1] 的值。因为刚开始 dp[i] 的保存第一行的值的,现在更新为保存第二行的值。

(3)、同样的道理,按照这样的模式一直来计算第二行的值,顺便把第一行的值抛弃掉,结果如下
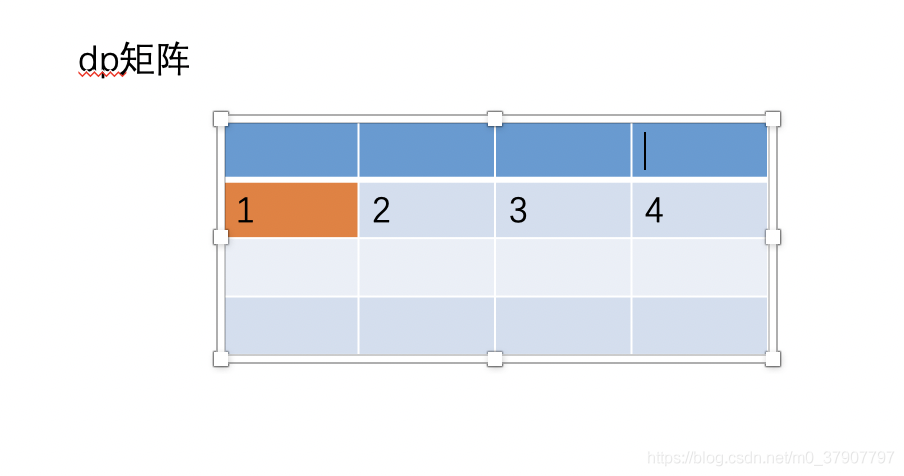
此时,dp[i] 将完全保存着第二行的值,并且我们可以推导出公式
dp[i] = dp[i-1] + dp[i]
dp[i-1] 相当于之前的 dp[i-1] [j],dp[i] 相当于之前的 dp[i] [j-1]。
于是按照这个公式不停着填充到最后一行,结果如下:
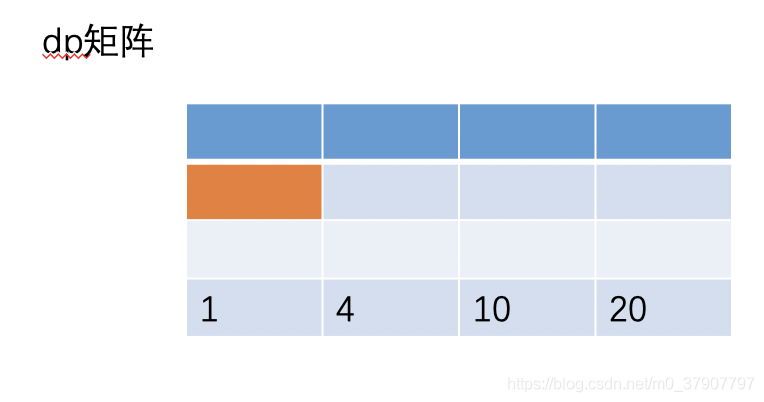
最后 dp[n-1] 就是我们要求的结果了。所以优化之后,代码如下:
案例2:编辑距离
接着我们来看昨天的另外一道题,就是编辑矩阵,这道题的优化和这一道有一点点的不同,上面这道 dp[i] [j] 依赖于 dp[i-1] [j] 和 dp[i] [j-1]。而还有一种情况就是 dp[i] [j] 依赖于 dp[i-1] [j],dp[i-1] [j-1] 和 dp[i] [j-1]。
问题描述
给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
解答
昨天的代码如下所示,不懂的记得看之前的文章哈:告别动态规划,连刷40道动规算法题,我总结了动规的套路
没有优化之间的空间复杂度为 O(n*m)
大家可以自己动手做下,按照上面的那个模式,你会优化吗?
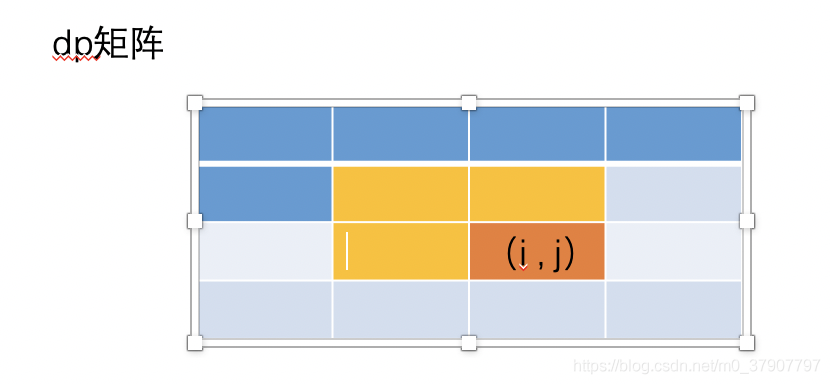
对于这道题其实也是一样的,如果要计算 第 i 行的值,我们最多只依赖第 i-1 行的值,不需要用到第 i-2 行及其以前的值,所以一样可以采用一维 dp 来处理的。
不过这个时候要注意,在上面的例子中,我们每次更新完 (i, j) 的值之后,就会把 (i, j-1) 的值抛弃,也就是说之前是一边更新 dp[i] 的值,一边把 dp[i] 的旧值抛弃的,不过在这道题中则不可以,因为我们还需要用到它。
哎呀,直接举例子看图吧,文字绕来绕去估计会绕晕你们。当我们要计算图中 (i,j) 的值的时候,在案例1 中,我们值需要用到 (i-1, j) 和 (i, j-1)。(看图中方格的颜色)
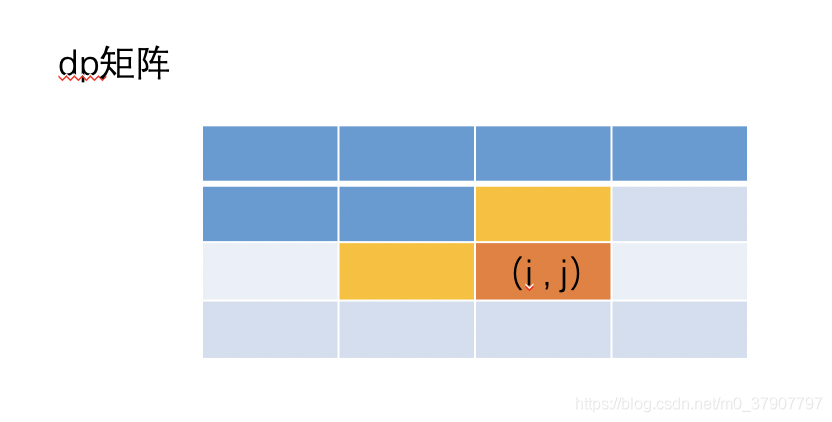
不过这道题中,我们还需要用到 (i-1, j-1) 这个值(但是这个值在以往的案例1 中,它会被抛弃掉)
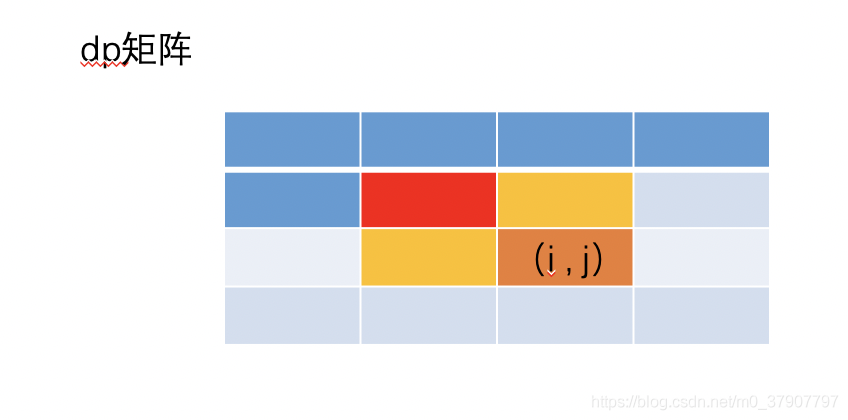
所以呢,对于这道题,我们还需要一个额外的变量 pre 来时刻保存 (i-1,j-1) 的值。推导公式就可以从二维的
dp[i][j] = min(dp[i-1][j] , dp[i-1][j-1] , dp[i][j-1]) + 1
转化为一维的
dp[i] = min(dp[i-1], pre, dp[i]) + 1。
所以呢,案例2 其实和案例1 差别不大,就是多了个变量来临时保存。最终代码如下(但是初学者话,代码也没那么好写)
代码如下
总结
基本 80% 的二维矩阵 dp 都可以像上面的方法一样优化成 一维矩阵的 dp,核心就是要画图,看他们的值依赖,当然,还有很多其他比较难的优化,但是,我遇到的题中,大部分都是我上面这种类型的优化。后面如何遇到其他的,我会作为案例来讲,今天就先讲最普遍最通用的优化方案。记住,画二维 dp 的矩阵图,然后看元素之间的值依赖,然后就可以很清晰着知道该如何优化了。


