什么是链表
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含两部分:数据部分和指向下一个节点的指针。链表与数组不同,它不是通过连续的内存地址来存储数据,而是通过节点之间的指针连接来组织数据。
从底层数据结构来看数组与链表区别:
数组中的元素在内存中是连续存储的,这意味着数组的第一个元素的内存地址加上元素大小乘以索引值,就可以得到任意元素的内存地址。而链表的每个节点通常在堆上分配内存,节点之间不需要连续的内存地址。

形态各异的链表结构:
单链表:
单链表是最常见的,最简单易用的。前面我们说到链表通过指针将一组零散的内存块连接起来,而内存块可以称为链表的节点,为了将所有的结点串起来,每个链表的节点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示为next,叫做后继指针,head为指向链表首节点的引用,如果节点相当于火车车厢,head就相当于火车头。
接下来请大家跟着我的步伐,我来带大家走进链表城堡的大门。首先我们要创建一个结点为Node类,里面有数据域和指向下一个节点的引用;如下代码所示:
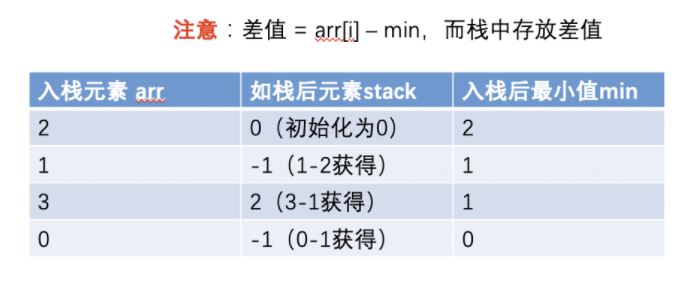
接下来我们来剖析链表的插入操作,如图所示:
然而新手在进行操作的时候一般容易陷入一个坑,导致引用错误。如下代码所示:

此时我们会发现这段代码最终会使得q.next=q,也就是自己指向了自己,那么遍历整条链表时会发生数据域为3的火车车厢与火车头脱钩;我们只需在插入节点时将这两行代码调个顺序即可。
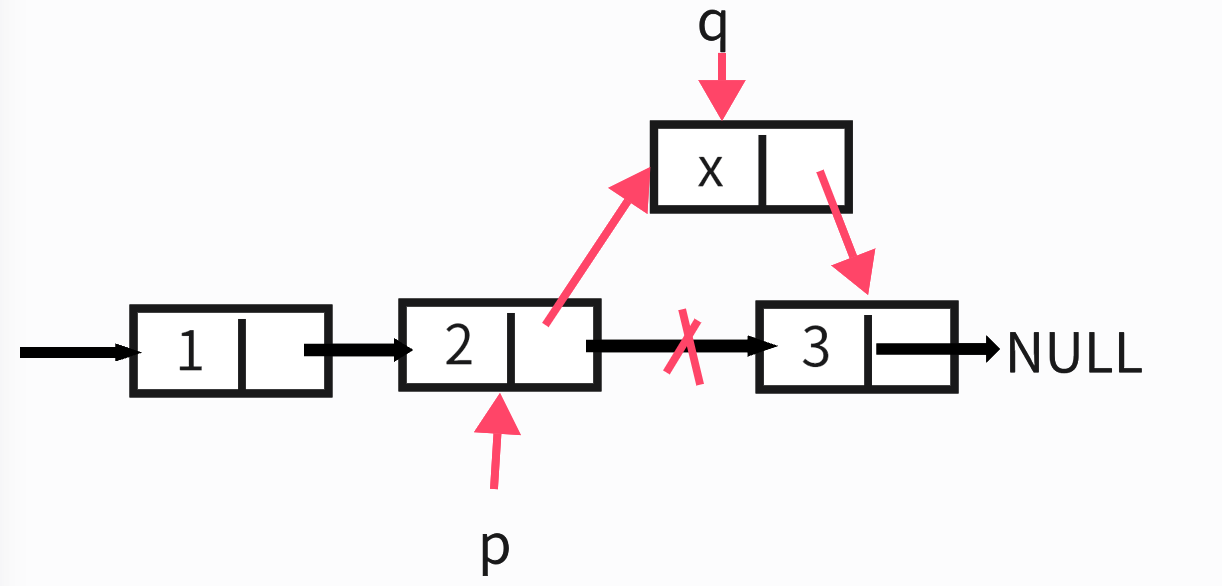
如果看懂了插入节点,那么删除节点就比较简单了,我还是画张图让你比较清晰的了解;
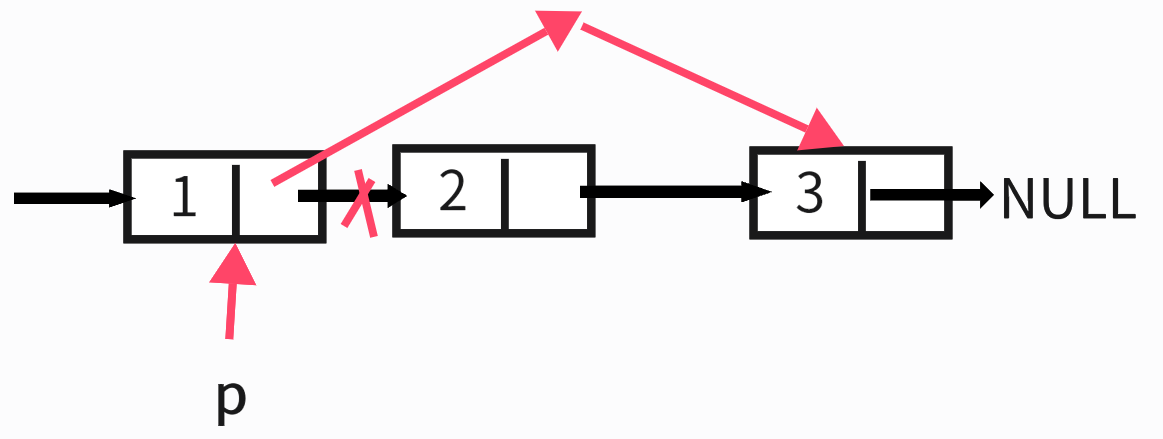
如上图所示,假如我们要删除数据域为2的节点,只需一行代码
了解完了单链表的插入,删除节点之后,有些读者可能会有疑惑,那如何遍历单链表呢?我们一般会先创建一个空节点,就是数据域为空,这样可以避免特殊情况的判断,比如删除节点时,如果链表为空,那上述的代码就不行;那么我们创建的空节点就相当于哨兵,画个图如下所示:

在哨兵模式下的遍历链表代码如下:
然后我对单链表的初始化,插入节点(尾插法),删除节点,打印链表做一个小小的总结,代码如下:
循环链表:
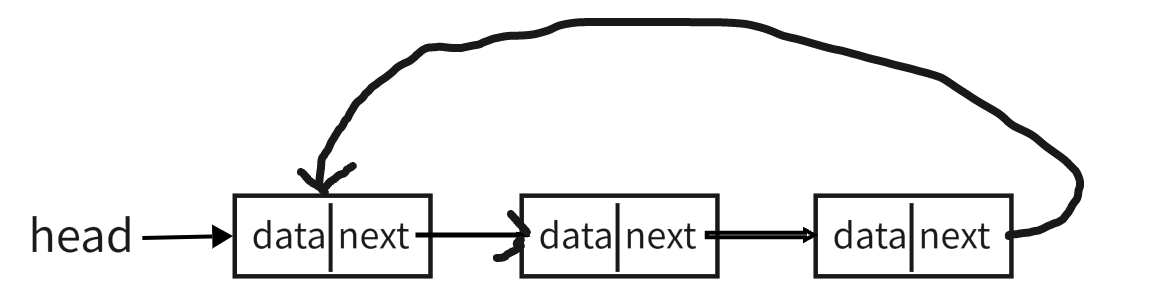
循环链表和单链表的区别在于它的尾节点的next引用指向头节点的引用,这样的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。如图所示:
双向链表:
双向链表是一种链式数据结构,它由一系列节点组成,每个节点包含数据部分和两个指针(或引用),分别指向前一个节点和后一个节点。这种结构允许双向遍历,即从链表的头部向前遍历到尾部,也可以从尾部向后遍历到头部。如下图所示:

从图中可以看出双向链表的实现通常需要更多的内存空间,因为每个节点需要额外的指针来存储前驱节点的引用。但这也会带来一些好处,比如在进行插入,删除节点操作时可以快速访问到要操作节点的前一个节点和后一个节点,这实际上运用了空间换时间的思想。
链表的应用场景:
在我们的实际工作中,链表主要用于动态的管理一个数据集合,这个集合需要频繁的进行插入和删除操作。还可以用于LRU缓存淘汰算法,由于缓存内存是有限的,所以将最近最少使用的数据淘汰掉,更有效的提高缓存的性能。
小结:
今天我给大家讲解了链表这个数据结构,从底层内存分布分析了它与数组的区别,对于不连续内存分布的空间用链表存储数据非常合适,它可以动态的插入,删除数据。另外我还介绍了几种链表的结构,其中用的最多的是单链表,与双链表不同的是它是一种时间换空间的思想。另外补充一点从时间复杂度来说,数组在随机访问时为o(1),而链表为o(n),在插入删除时数组为o(n),链表为o(1)。