
字符串匹配Boyer-Moore算法
关于字符串匹配算法有很多,之前我有讲过一篇 KMP 匹配算法:字符串匹配 KMP 算法,不懂 kmp 的建议看下,写的还不错,这个算法虽然很牛逼,但在实际中用的并不是特别多。至于选择哪一种字符串匹配算法,在不同的场景有不同的选择。
在我们平时文档里的字符查找里

采用的就是 Boyer-Moore 匹配算法了,简称BM算法。这个算法也是有一定的难度,不过今天,我选用一个例子,带大家读懂这个字符串匹配 BM 算法,看完这篇文章,保证你能够掌握这个算法的思想。
首先我先给出一个字符串和一个模式串

接下来我们要在字符串中查找有没有和模式串匹配的字串,步骤如下:
坏字符
1、
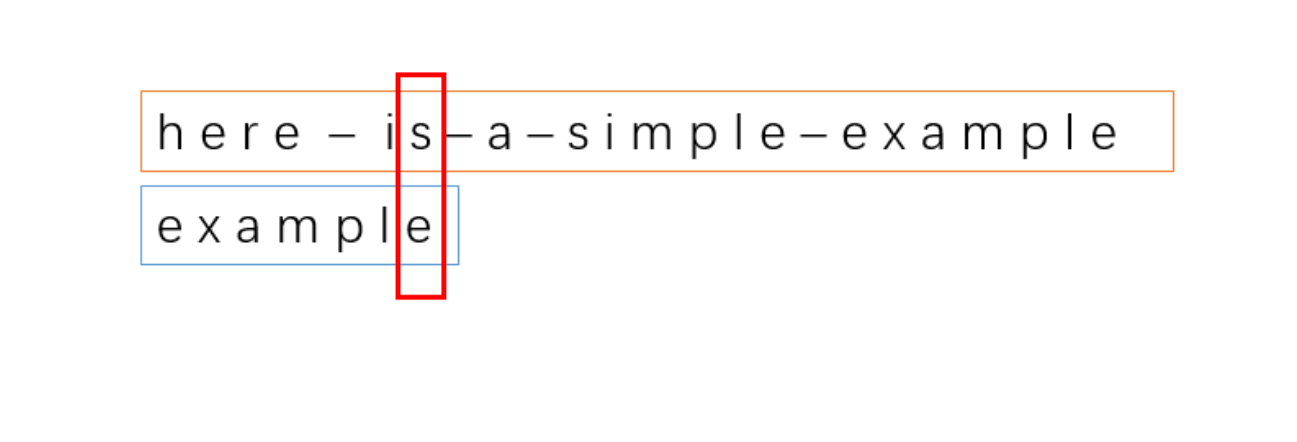
和其他的匹配算法不同,BM 匹配算法,是从模式串的尾部开始匹配的,所以我们把字符串和模式串的尾部对齐。
显然,从图中我们可以发现,s 和 e 并不匹配。这时我们把“s” 称之为坏字符,即代表不匹配的字符。而且我们可以发现,s 和模式串中的任意一个字符都不匹配,所以这时,我们可以直接把模式串移动到 s 的后面。
2、

从图中可以看出,此时 p 和 e 不匹配,所以 p 是一个坏字符,不过,我们可以发现 “p” 包含在模式串中
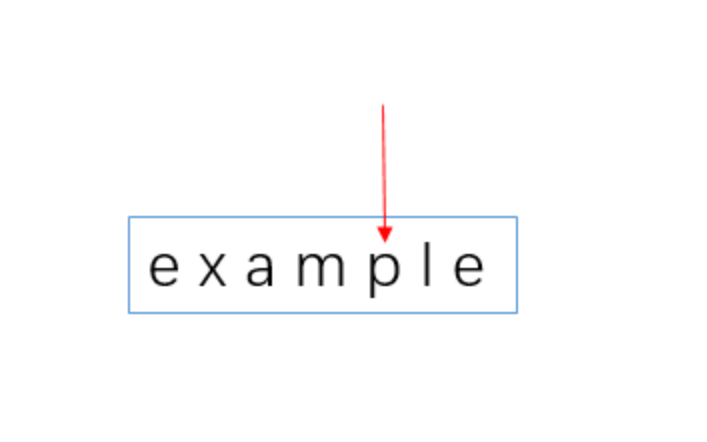
所以,我们不能像第一步那样,把模式串直接全部移到 p 的后面去,而是移动两位,让两个 p 对齐。
4、

那么问题来了,当我们碰到碰到坏字符的时候,该移动几位呢?
下面我和大家讲一下这个问题,首先我们要算出模式串中两个字符的下标。这两个字符分别是
(1)模式串中与坏字符对应的那个字符的下标,在我们上面那个例子中,就是 e。
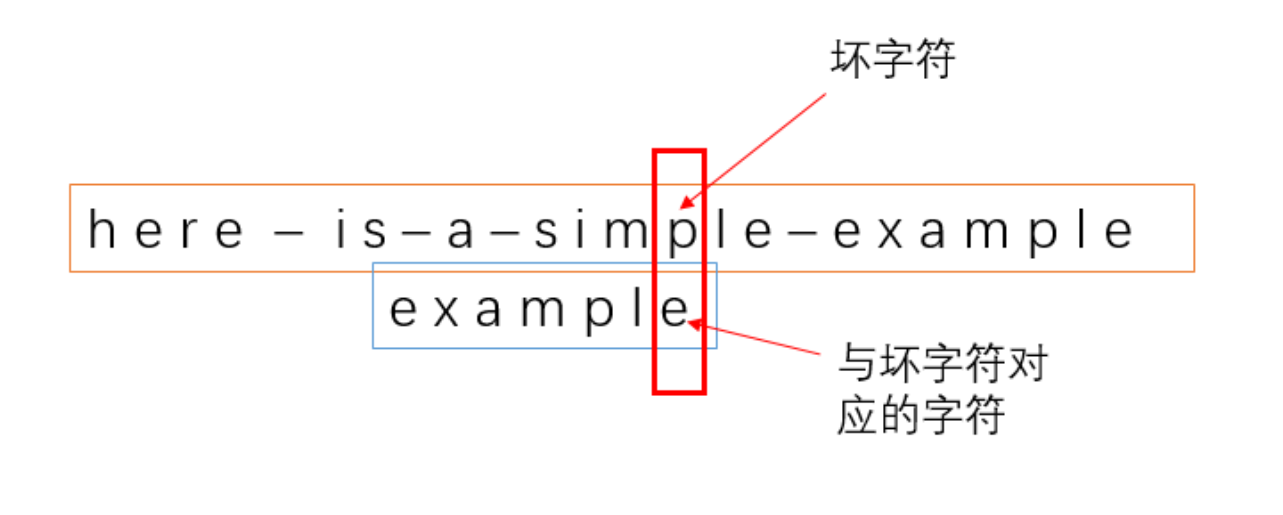
显然,这个 e 的下标是 6(从0开始算起)。我们用变量 t1 来代表这个字符的下标吧。
(2)坏字符在模式串中的下标,在我们上面那个例子中,坏字符在模式串中的下标为 4,我们用变量 t2 来代表这个下标,如图
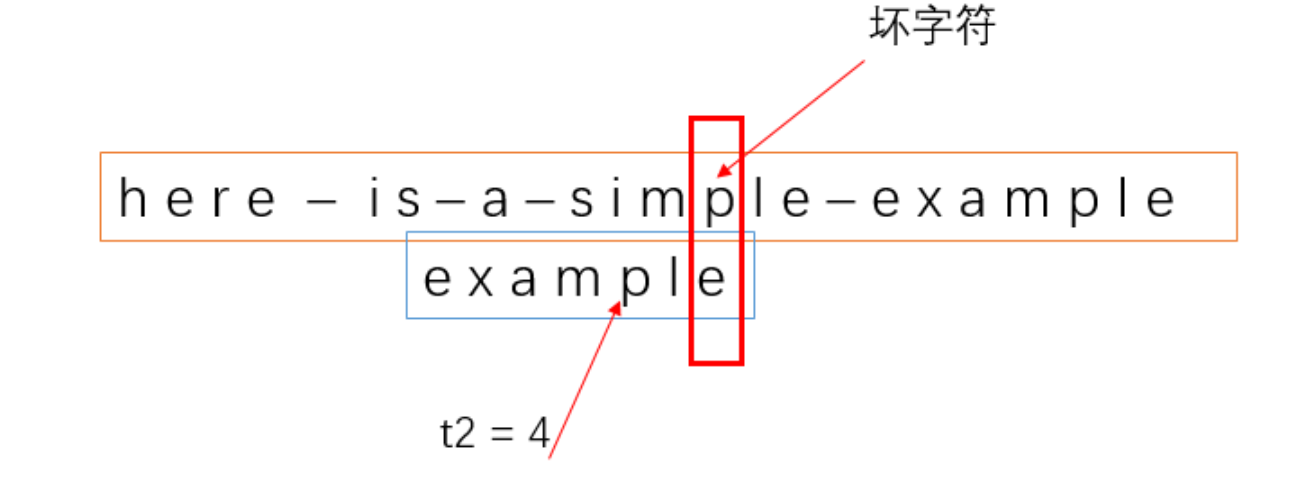
找出这两个字符的下标之后,我们就可以计算移动的位数了
移动的位数 = t1 – t2。
例如上面的例子步骤 2 中 t1 = 6, t2 = 4,所以移动了 t1 – t2 = 2 位。
(1)这个时候可能有人会问了,那如果模式串中有多个 p 呢?
答是如果有多个,我们只计算最右边的那个(当然是移动的位数越少越安全了)
(2)可能又有人会问,那如果模式串中并不存在坏字符呢?例如步骤1
答是如果不存在的话,我们把 t2 赋值为 -1,即 t2 = -1。所以我们步骤 1 中移动了 t1 – t2 = 6 – (-1) = 7 位。
好了,现在我们已经解决了遇到坏字符之后,应该移动多少位的问题了。
好后缀
我们继续匹配
5、

匹配,所以继续匹配前面的字符
6、

匹配,继续匹配前面的字符
7、

匹配,继续匹配前面的字符
8、
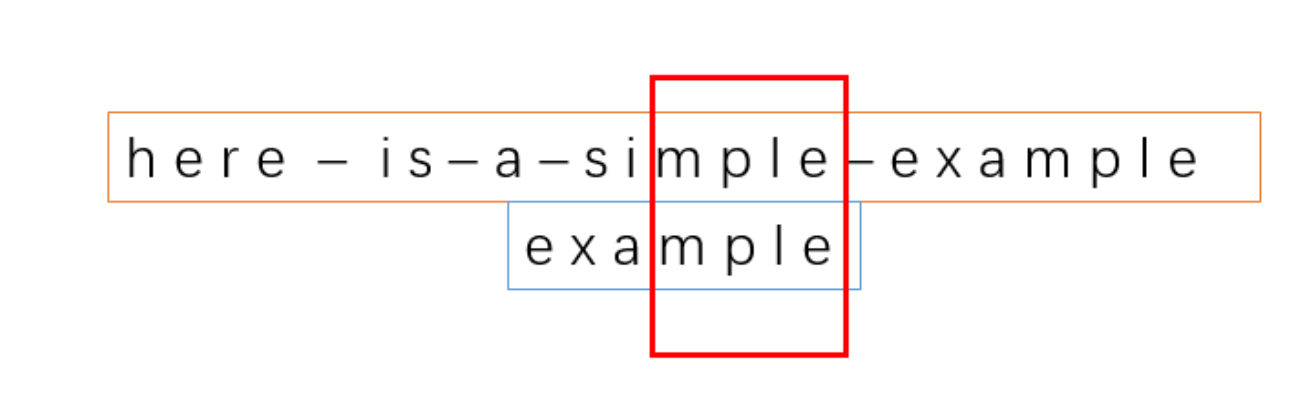
匹配,继续匹配前面的字符
9、
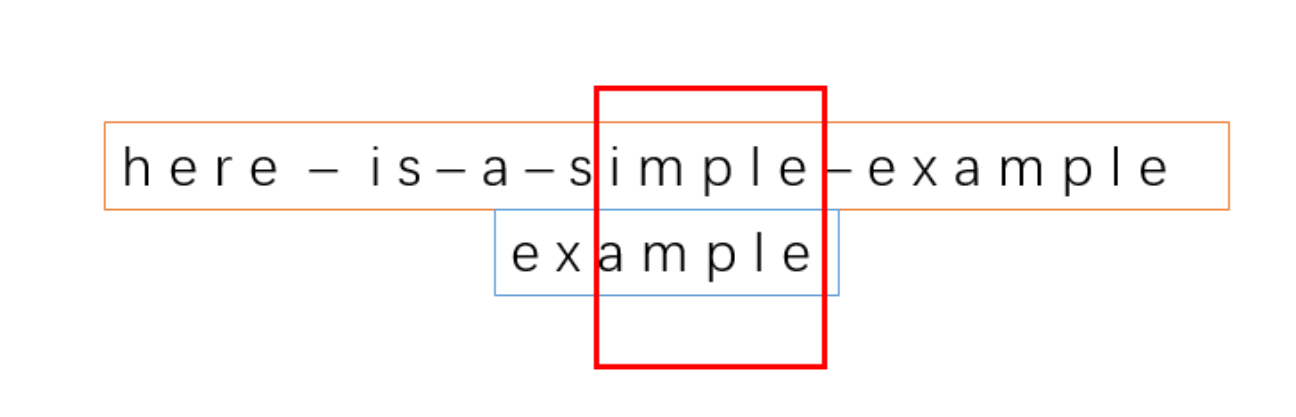
遇到坏字符 i,按照我们前面的规则,可以计算出 t1 = 2(就是a的下标)。t2 = -1(因为模式串不存在坏字符)。所以移动的位数是 t1 – t2 = 3。
但是,我想问一下,这是最好的移动方式吗?有没有更好的移动方法呢?接下来我就和大家介绍一种更好的方法,这种方法就是根据好后缀来移动位数。首先我们先介绍下啥的好后缀。
在上面的例子中,我们发现 “mple” 是能够成功匹配的
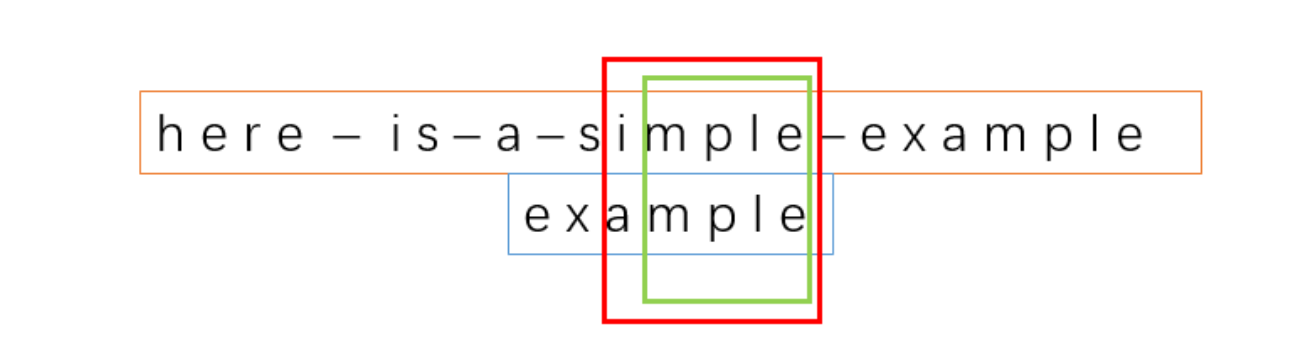
我们把这些能够成功匹配的子串,称之为好后缀,所以呢,e,le,elp,mple 都是好后缀
因为 e, le, elp在之前的步骤中,也是能够成功匹配。不过 mple 是最长的好后缀。
接下来我们要在模式串的前面寻找与好后缀匹配的子串,这句话的意思就是说,我们要在模式串中寻找这样一个子串s:s 与好后缀匹配,并且s中的字符不能与好后缀有重叠。
我举个例子吧,例如有模式串 abcddab,然后好后缀分别是 b, ab, dab。那么与好后缀匹配的字串有 b,ab。(因为abcddab前面中的b可以与好后缀 b 匹配,前面的 bc 与好后缀 bc 匹配)。不过,没有与好后缀 dab 匹配的子串。
那么问题来了,如果我们找到了多个这样的子串的话,我们要选择哪一个呢?例如上面我们找到了两个,分别是 a,ab。
这个时候,我们选择与比较长的那个好后缀匹配的子串,例如,上面的例子中,我们会选择 ab,我们把这个被选中的子串(ab)称之为好前缀吧(我是为了后面方便描述,才给它这个一个称呼)。
找出了好后缀和好前缀之后 ,我们就可以知道要移动几位了,公式如下:
移动的位数 = 好后缀的下标 – 好前缀的下标。
当然,好后缀有多个,我们是选择和好前缀匹配的那一个。那么好后缀的下标怎么算呢?,计算方法是按照好后缀的最后一个字符的下标为准,例如模式串 abcddab 中好后缀 ab 的下标为 6(下标从 0 开始算起)。好前缀下标的方法也是一样,以最后一个字符的下标位准,例如模式串 abcddab 中,好前缀 ab 的下标为 1。
这里可能有人会问,那如果不存在这样的好前缀呢?如果不存在的话,就用 -1 充当好前缀的下标。
知道了移动位数之后,我们继续来匹配我们上面的例子
10、
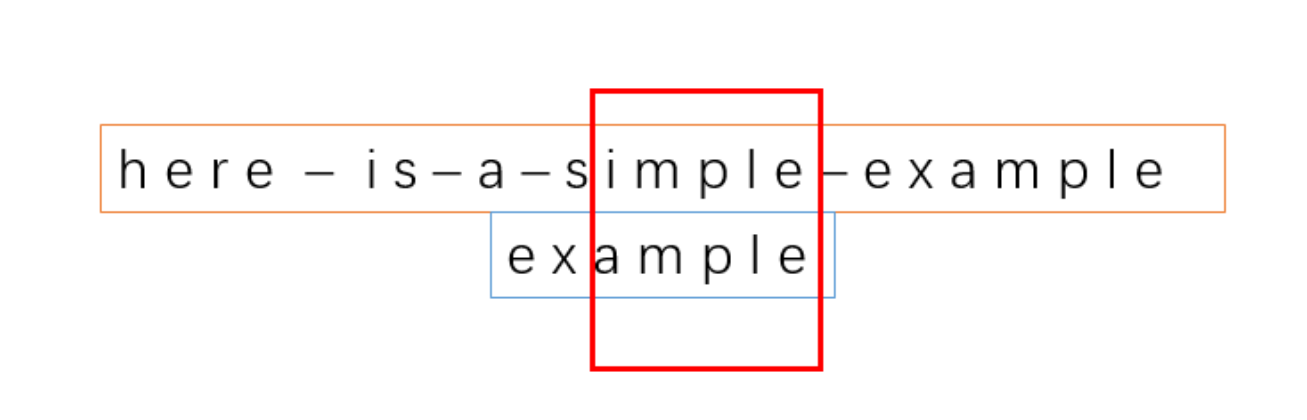
好后缀是 e, le, ple, mple,但是模式串中只有一个子串能够与好后缀 e 匹配,所以好前缀为 e。
显然,这个时候好前缀 e 的下标为 0,好后缀 e 的下标为 6,所以移动的位数为 6。如果按照我们最开始坏字符的移动规则的话,只能移动 3 位,而用好后缀可以移动 6 位。
选择坏字符的规则还是好后缀?
11、

可能有人会问,两个规则我们应该要选择哪一个呢?
答案很简单,把两个规则的移动位数都算出来,选择移动位数多的就是了。
这里 p 是坏字符,并且不存在好后缀,所以采用坏字符的规则,移动 2 位。
12、
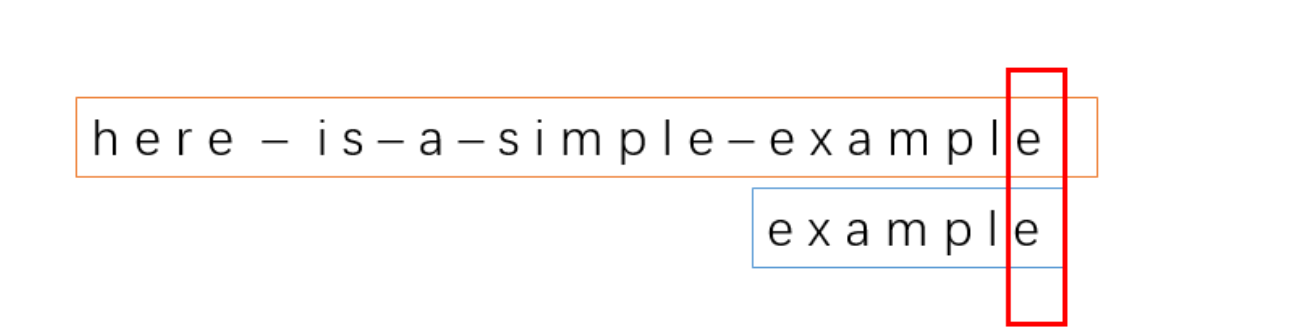
这个时候,我们可以发现,模式串的字符全部都匹配了,这也意味着匹配结束了。
总结
这篇文章我是采用直接举例子的方式来讲,我觉得这样反而容易懂,并且在讲的过程中,可能没有讲的那么全,这是因为我不想说的太全,因为把所有情况都罗列处理的话,相信你容易晕。所以我才用这种方式,让你先懂了这个 BM 的算法思想,之后的细节,你可以再去琢磨。
为了讲清楚这个算法,也算是绞尽脑汁,特别是为了能够以最简单的方式来讲解好后缀的规则,停笔思索了好久,最后也百度搜索了几篇文章,看看别人都怎么讲,还翻开了我之前购买的数据结构与算法的专栏,,,最后结合自己的想法写了出来。希望这篇文章,能够让你读懂给 BM 算法,这个算法的核心就是坏字符和好后缀了,相信你一定能够搞懂!
